
Building a content graph, part four; Middleware for linking information
So far, I have talked about some of the information-centred components of a content graph; Content graph items, Content graph authors and the Tellura Content Graph taxonomy. One information-centred component remains to be defined and populated; the graph database, and I’ll be covering that in a later article.
However, a crucial part of the architecture is the part that holds these components together. I describe this as semantic middleware; software that acts as a messenger, having interfaces to the different graph components, passing information between all of them and processing that information for further use.
In this article I will describe how to build semantic middleware software that will communicate with Drupal and with PoolParty (and eventually with GraphDB) via their respective Application Programming Interfaces (APIs). It will use retrieve and analyse information from these components, and analyse and process them into useful semantic information. Here is how this article fits in the flow of earlier and later articles:
- Guiding principles for content graphs
- Content design for content graphs
- Taxonomy design for content graphs
- Middleware design for linking information (this article)
- Information model design for content graphs
- Using a graph database to tie everything together
- Managing a graph database using the api
In this article
I will cover some technical detail about using the cross-platform development tool Xojo (https://www.xojo.com). It is not strictly necessary to follow the code; it is more intended to describe how all of the steps hang together. Get in touch if you'd like to know more about the practical processes of building semantic software like this.
All of the steps in this article are contained in a program that I built called Content graph middleware. I will describe the main programming steps, though not everything (that would be too dull for much of the audience).
Retrieving and processing content information from Drupal ^
I mentioned in article 2 that I have a content management environment in which I have stored content objects of two types; Content graph items and Content graph authors. I have chosen to keep these as separate content types because there may be value in the future in managing Person objects (a Person may belong to an Organisation or a Project, both of which are plausible content classes that we might want to use), and our collection of Authors would be a good starting point.
For our current purposes, I want to be able to create linked information about Content graph items and Content graph authors. This is hinted at in the Content graph item collection, but it is not very useful since individual authors are not available from arXiv. Instead, I processed the field that contained multiple authors and output a list of individual author names, together with their URIs (using Drupal Views; another exercise for the audience, I’m afraid).
Separately I processed the Content graph items in order to output a View containing the URI and each individual author (so a single article might appear three times in the list, once for each author name).
Here is the Xojo program UI for this, showing the populated lists:
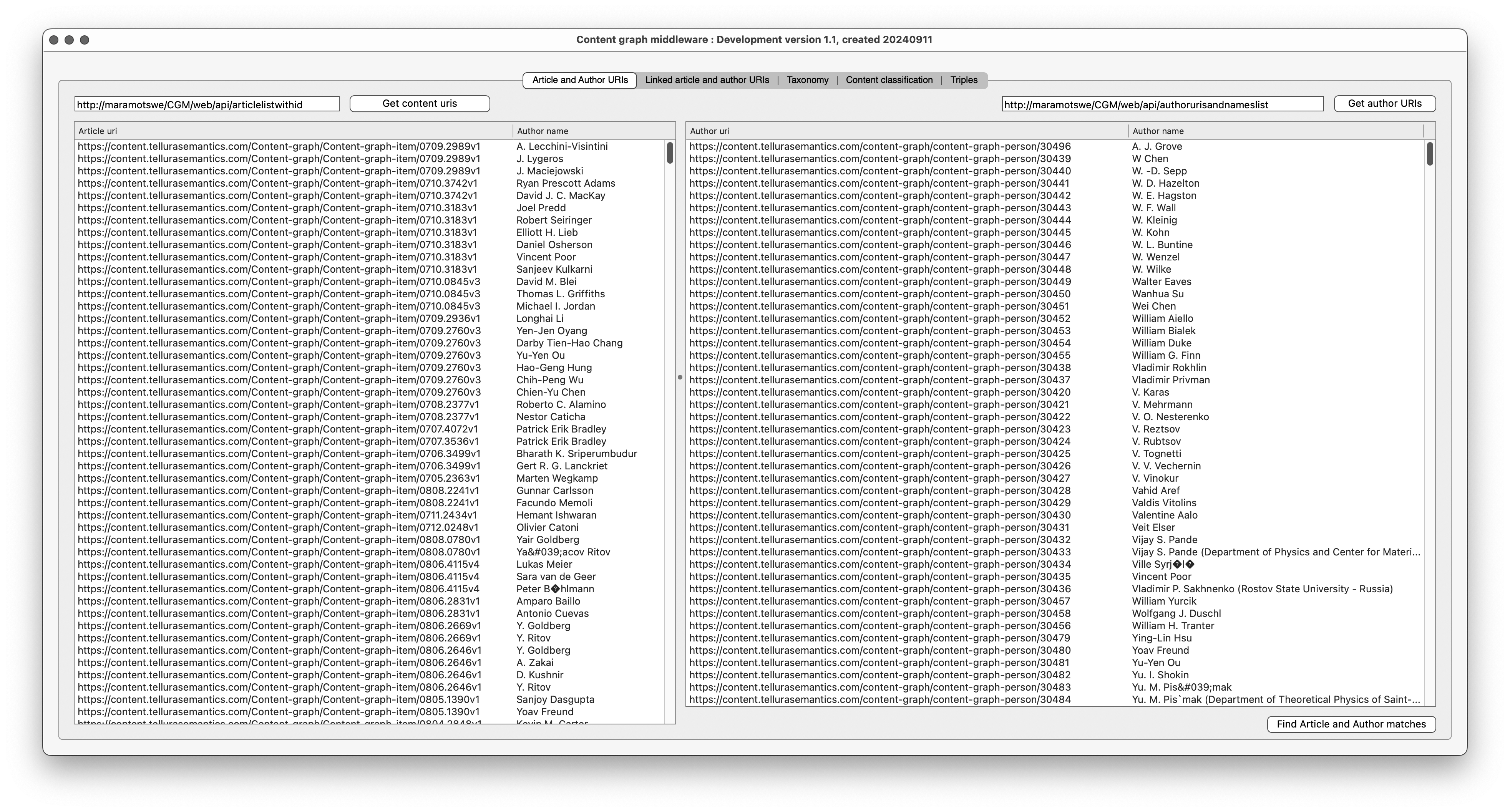
Let’s look at the information in this window. On the left there is a two-column list showing a URI for a Content graph item and an author name. You will see that the first three rows have the same URI (ending in 2989v1) and different author names. On the right is another two-column list showing a URI for a Content graph author and the author name.
Now for a deeper dive; let’s see how this information was extracted from Drupal.
You will see that there is a web uri above each of these lists. On the left this is http://maramotswe/CGM/web/api/articlelistwithid (you can't follow this link). This uri points to a Drupal View. The highlighted section of this View shows the fields that I want to retrieve.
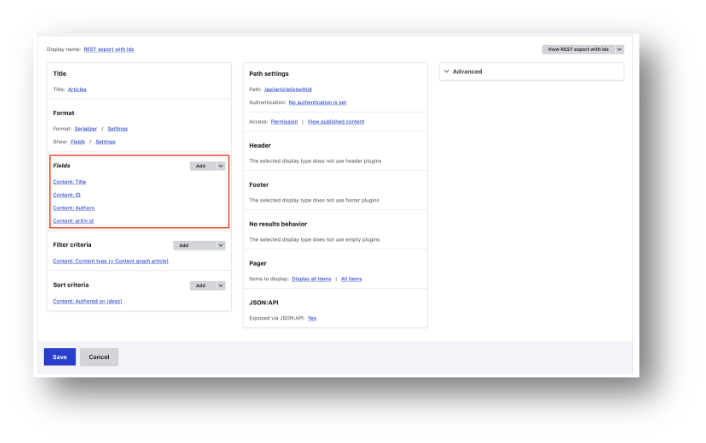
When I load this View using a web browser, I see this:
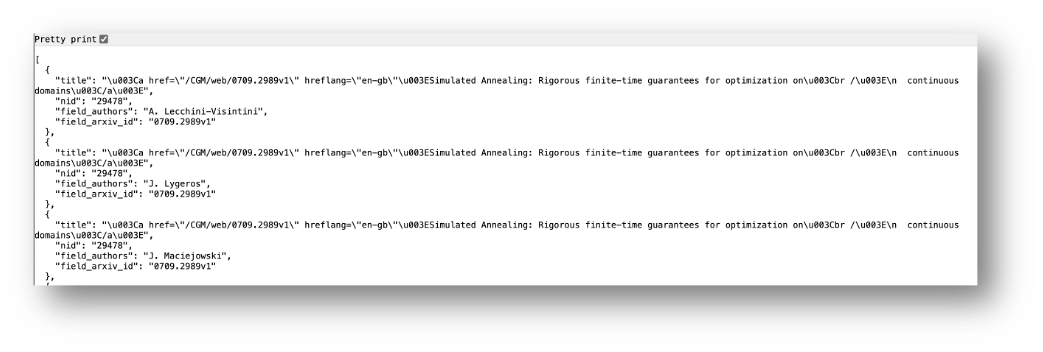
You can see the three json child objects, each with identical information apart from the author name.
Having programmatic access to JSON like this makes it very easy to consume information from a Drupal View. Here is how I did it in Xojo. The command button labelled “Get content URIs” in the screenshot above sets up an object called a urlConnection with the instance name ucDrupalArticles. This urlConnection handles the process of sending a request off to a RESTful endpoint and receiving the response. Here is the code. Briefly, it clears any existing structures (request headers, JSON object), then sets up the api method and the request uri, and sends it off to the endpoint (in this case, http://maramotswe/CGM/web/articlelistwithid) (you can't follow this link). The response is then sent to another method (within the program) called processJSONArticles (I have been accused of undue verbosity in my names for items in code, but it’s the only way I can follow my own code).
// Clear the URLConnection |
The processJSONArticles method is shown below. The listbox is cleared first. Next, the incoming JSON package is selected and looped over. For each child node I constructed a new URI based on the arXiv id and put this in the first column of the listbox. Then I added the author name to the second column.
lstDrupalArticleURIs.RemoveAllRows |
Figure 1 (see earlier) shows the result. Note that I was concerned that the resulting URIs may contain a dot “.”. However the relevant rfc (rfc3986) says that it’s legal.
The next step in this process, now that I have URIs for Content graph items and authors, and author names, is to run a comparison of names. This enabled me to link the URIs together. Here is the code:
dim numMatches as Integer = 0 |
This is a simple comparison method; each author name is loaded from the left list, and compared against each author name in turn from the right list, and, where these match, the URIs for Content graph items and Content graph authors are added to a new listbox.

Now I have the matching article and author URIs, I can use the command button on this tab to generate triples:
dim generatedTriple As string |
This uses a one-line utility method called MakeTriple. This just takes the subject, predicate and object strings and wraps them with the appropriate strings to format them correctly as n-triples data:
return "<" + subject + "> " + "<" + predicate + "> " + "<" + object + "> ."
The final result is collected in another listbox:

Later, when I’ve added the tagging triples (see below) I will write these out to an n-triples file.
Aside; why are these URIs different from the URIs in Drupal? ^
The simple answer is consistency. I decided that the overall architecture in the content graph would look better if all objects had URIs based on [thing].tellurasemantics.com. Also, I decided that I wanted to make use of the arXiv id where I could, so minting my URIs in this way made the information completely explicit – never a bad thing in the Semantic Web world.
Using the PoolParty Extractor to classify content ^
Having linked Content graph items with Content graph authors, let’s turn to classification of Content graph items using a taxonomy. As I showed in part 1, classification of content objects using concepts from a taxonomy is one of the most powerful aspects of a content graph.
Traditional tagging in a content management system involves creating what is effectively a hard database link between a content item and a keyword drawn from an internal keyword list. Like many traditional systems, the implicit assumption is that you never move outside the boundaries of the content management system. If you did want to classify other content with that same keyword, that’s practically impossible because the assignment of database links like this are infeasible for external applications. Another important factor, also discussed earlier, is that because the tagging is bespoke for this content management system, when (not if) the organisation decides to move to another such system, the best you can hope is that the content can be transferred with some fidelity. It is extremely unlikely that the tagging will survive the transition to a new environment.
Building a content graph based on content objects and taxonomy concepts is a way of separating the two types of object while still allowing them to link together. If you have content objects linked to an external taxonomy using semantic relations then you have the capacity to use that taxonomy to also classify content in other systems; a project management system, or a digital asset management system, a logistics system, or an organisation information system; all can have objects classified using a common taxonomy.

Figure 6 Extended content graph
To build this part of the content graph, I need to do a number of things:
- Identify a content object (already done)
- Build a taxonomy that is suited to the content (also done)
- Analyse the content compared against the taxonomy to identify potential tags
- Confirm the relevant tags for this content
- Build the triples for the tags
For this purpose I’m going to use the PoolParty Extractor. This is a component of the PoolParty suite that takes a content object, analyses it and suggests matching taxonomy concepts. There is a UI for the Extractor, which I showed back in part 3, but the most common use case is to write an application that talks to the PoolParty API. I’m using Xojo to do this.
The first step is to load a collection of content objects (actually, in this case, a folder of files). In the image below I have done this and selected one of the objects.

The content for the object has loaded into the middle panel. As a human I am able to read this content and decide what it's about. However, I want some help from the Extractor. Choosing the Suggest concepts button starts the Extractor analysis process. The program uploads the file to the Extractor and waits for the response. This comes back in the form of a JSON package containing the raw tagging data. This data is quite extensive and I don’t propose to go through it in detail here. The information that I’m really interested in collecting is the concepts. The JSON fragment below shows that we have, for each concept, an id, a tagging score (which may be useful if you want to include relevance ranking), the URI and the preferred label, plus other information.
"concepts" : [ { |
Here is the Xojo code that runs the Extractor api extract method.
// Clear the request ready for a new one, if necessary |
Having cleared the request headers, ready for a new request, I added the authentication details, then set up the URI for the request. This uses the extract method of the Extractor, which requires as parameters in this case the taxonomy project id, the corpus management identifier (more on this below) and the required number of concepts.
This application uses some bespoke code to help set up the request headers correctly to handle the file upload; the method requires that the request uses POST and has a multipart/form-data mime type, including the file content as the payload. To set the request running I pointed the SendSync method for the urlConnection called ucExtractConceptsFromFile (no apologies for the verbose name, as I explained earlier). The SendSync method returns a JSON package which I passed to another routine in order to pull out the relevant data for the checked listbox. Here is the Xojo code.
dim numberOfConcepts as Integer |
This code takes as its input the JSON package retrieved from the PoolParty Extractor. It selects one part of the package (“Document” > “concepts”) and then goes through each member of the concepts child node, pulling out the English prefLabel and the URI. The prefLabel is used as the label in the listbox, while the URI is stored in the celltag. Xojo listboxes have the nice property of being able to store an invisible tag alongside the information displayed in the list, in this case the URI for the concept. Shortly I’ll use that celltag to provide the URI for the tagging triple.
At this stage the user is able to check on the tagging suggestions. Now, we could have automated this entire process, and simply accepted the suggestions, but let’s look at these suggestions.

We have a list of 20 suggestions for relevant tags for this content. Looking through the content with human eyes it is obvious that some of these concepts are more relevant than others. Clearly Bayesian decision making is a good choice, as is Markov Model and a couple of others, but some are clearly not at all relevant. That is why I included checkboxes in the list. As a human, with a human’s insight, I should have the final say over what concepts I use to classify my content.

Aside: the corpus management identifier ^
When you use the Extractor in PoolParty, you need to provide a piece of content and the taxonomy project where the concepts are stored. In addition, you need to have access to the corpus management for that project. In the previous article I described how building and analysing a content corpus creates a sophisticated structure that enriches and enhances the value of the taxonomy. This adds value to the comparison process, improving the quality of results.
Building the triples ^
Now that I’ve got the content and have selected the relevant concepts for tagging, I can generate the triples. For this I need to use the URI for the content object (which I can get from the arXiv id at the top of the content and also in the filename), together with the URI for each tagging concept (which, as mentioned earlier, is stored in the celltag for the concept in the list), and then create triples using the two tagging predicates: https://content.tellurasemantics.com/Content-graph/hasSubject and https://content.tellurasemantics.com/Content-graph/subjectOf . These derive from the information model and are intended (hopefully clearly) to convey the fact that the content object has a subject with the URI of the concept. Since the information model defines this as an inverse relation, there is a corresponding subjectOf triple. For this reason, each tag gets two triples, describing the two halves of the inverse relation.
Here is the Xojo code.
dim generatedTriple As string
dim generatedInverseTriple As String
dim predicate1 as string = "https://schema.tellurasemantics.com/Content-graph/hasSubject"
dim predicate2 As string = "https://content.tellurasemantics.com/Content-graph-manager-model/subjectOf"
dim uriFromFilename as string
for i as integer = 0 to lstConceptsToTag.RowCount - 1
if lstConceptsToTag.CellCheckBoxValueAt(i,0) = true then
// the human confirms it's a plausible tag
// Get the content item uri from its filename
uriFromFilename = generateContentURIFromFilename(lstTextFiles.CellTextAt(lstTextFiles.SelectedRowIndex))
generatedTriple = makeTriple(uriFromFilename, predicate1, lstConceptsToTag.CellTagAt(i,0))
generatedInverseTriple = makeTriple(lstConceptsToTag.CellTagAt(i,0), predicate2, uriFromFilename)
lstOutputTriples.AddRow(generatedTriple)
lstOutputTriples.AddRow(generatedInverseTriple)
end if
next
This is how the generated triples look in the program UI; the four confirmed tags result in eight triples, as shown here.

End of Part 4 ^
In this article I’ve described how we go about using semantic middleware to link objects (and their corresponding systems) together. While this is all working code, it is not yet complete. For example, in a real situation I would want to tag content at the creation stage. I don’t have that luxury here since I’m using existing content. In an ideal case I would have programmatic access to the full content of the content objects; in our case the content object has basic information, and I needed to access the full content by downloading and processing pdf files from the arXiv website. I have tried to make the cases I'm dealing with as close to real world as possible, but I have to be pragmatic; I don't have the access I would like.
The next best thing is to be able to inspect the existing content, get suggestions from PoolParty about relevant tagging concepts and choose the right ones. That’s what I’ve done here. The final set of triples defines a graph of Content graph items linked to Content graph authors and also to taxonomy Concepts, linked using predicates drawn from the information model.
Another piece that’s missing at the moment is where these triples will all end up. For now, my middleware application simply writes the triples out to a file in N-triples format. Ideally, and to conform with the principle of using APIs where we can, I should be able to send these triples to a graph database. That will be covered in Part 6. Before we can get to that, we have to take some time to talk about the information model that we’re using for our content graph. That is the subject of the next article.