
A web content graph, part three; Taxonomy design
This article is about the taxonomy component of a content graph. Although the idea of a content graph is centred on links between content objects (the previous article discussed Content graph items and Content graph authors, which suggest an inverse relation of hasAuthor and isAuthorOf), when we look in more detail at content-rich objects such as Content graph items we can exploit another dimension of semantic relations; we can apply classification. Classification using a taxonomy enables us to investigate the aboutness of content. In this article I’m going to describe how I built a taxonomy that would be tailored for classifying or tagging the content that we’ve already created. Here is how this article fits in the flow of earlier and later articles:
- Guiding principles for content graphs
- Content design for content graphs
- Taxonomy design for content graphs (this article)
- Middleware design for linking information
- Information model design for content graphs
- Using a graph database to tie everything together
- Managing a graph database using the api
In this article
Setting the scene ^
In this series of talks I am using the PoolParty semantic suite of tools. PoolParty is a commercial product that has at its heart a taxonomy management system useful for creating and managing taxonomies based on the Simple Knowledge Organisation System (or SKOS) format. SKOS is very useful for handling taxonomy information for a number of reasons:
- It stores rich data properties about taxonomy concepts, beyond just keywords. These include preferred labels in multiple languages, synonyms and definitions.
- It allows for a variety of object relations between taxonomy concepts, such as broader, narrower and related.
- As a flavour of RDF, it allows for the import of other ontologies (SKOS is itself an ontology based on the Resource Description Framework or RDF and thus is able to import other ontologies). This allows a taxonomy to take on other, bespoke, object and data properties.
- Every concept in a SKOS taxonomy has a Uniform Resource Identifier (URI). As well as conferring flexibility in terms of allowing mutable properties such as preferred labels without losing the identity of an unique concept, the URI is the foundation of the ability to link taxonomy concept information with other information objects (such as content) using semantic relations.
PoolParty also has some useful more advanced features, including the Corpus Management and Extractor tools. These are key to allowing us to analyse content and suggest concepts suitable for classification.
An initial taxonomy ^
For the source of content component in our content graph, I have been using the arXiv library which has a curated set of articles on scientific topics. These articles are tagged using a simple taxonomy (see here: https://arxiv.org/category_taxonomy). The category taxonomy has eight top-level categories with a second level of sub-categories. These are described using a two letter dotted nomenclature (so, for example, Computer Science / Artificial Intelligence is abbreviated to cs.AI).
While eminently suited to the needs of the arXiv library, I wanted to have a more elaborate taxonomy for building a content graph. So I built a simple taxonomy based on these categories and sub-categories, and elaborated and added further levels where it seemed to make sense from a taxonomy point of view.
This gave me an initial taxonomy that had some relationship in principle with the arXiv content. However, PoolParty offers the opportunity to build out and enrich a taxonomy based on a specific body of content, through a technique called Corpus Management.
Enhancing a simple taxonomy using Corpus Management ^
This technique involves analysing a large body of content, usually as a set of documents or website pages, and comparing it against a simple taxonomy. The analysis then shows a number of useful pieces of information:
- Concepts that occur in the taxonomy and also in the corpus of analysed content. This gives a confidence level of the fitness of the taxonomy to the content, since if most of the extracted concepts extracted from the corpus feature in the taxonomy then there is a good fit between the two; it feels like a well-designed taxonomy for this content.
- Concepts that occur in the taxonomy but do not occur in the corpus. This is a more nuanced set of results, because there may be a number of reasons for taxonomy concepts not showing up in the corpus:
- The corpus may not be comprehensive. If the sample of content is insufficient then some plausible taxonomy concepts may not appear in that content.
- There may be portmanteau concepts. For example, the taxonomy designer may have created a concept that concatenates several different concepts, such as Comets, asteroids and meteorites. If that precise string doesn’t appear in the corpus then it won’t show up as an extracted concept. In a case like this it might be worth splitting this into three concepts; Comets, and Asteroids, and Meteorites.
- The extracted concept may simply not be appropriate for the taxonomy.
- Word or phrases that occur frequently in the corpus of analysed content, but are not present as concepts in the taxonomy. This information is useful in identifying potential candidates for taxonomy concepts. If a word or phrase appears frequently in the content, then it may make sense to add a new concept to the taxonomy to cover it. This may seem a little nit-picking, but actually it informs the taxonomist’s work, because it points to changes that will improve the taxonomy.
In my case, I gathered together a corpus of 749 pdf documents as the source, and used the initial taxonomy of 150 or so concepts based loosely on the arXiv categorisation taxonomy.
In case you’re wondering where the 749 pdf documents came from, this was the result of a piece of software that I created using Xojo. I first used a Drupal View to give me a list of all of the pdf urls:

I copied this list and saved it in Excel format. There will be a lot of places in these talks where I leave the exact details of a process as an exercise for the reader, and this is one of them.
I then wrote a desktop application in Xojo that is designed to fetch a document from a RESTful endpoint. The UI is a little stark, but it does the job:
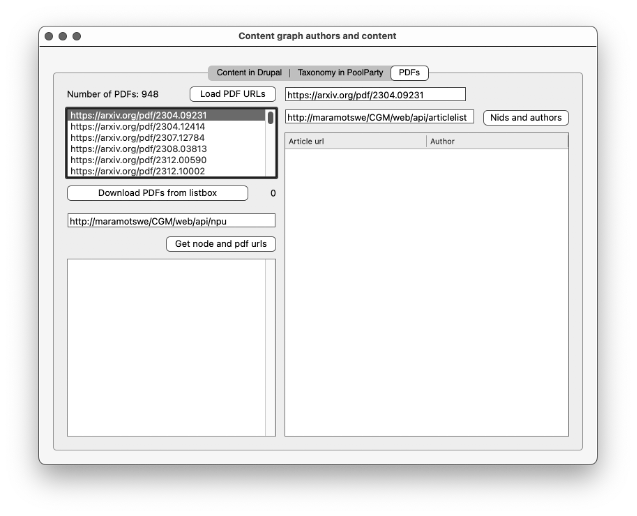
This program takes the content of each cell in the listbox to use as the RESTful endpoint. In the arXiv library it is possible to get the pdf for an article by constructing the url with a pdf and the document name, like this:
https://arxiv.org/pdf/[documentname]
I used the urlConnection module in Xojo to manage the communications. This is an extremely powerful tool for working with remote RESTful endpoints, and can work with streamed data or files. In this case I wanted the file, so I used the FileReceived event to manage receiving and saving the pdf down to my disk. Once I had the collection of files I could turn to Corpus Management in PoolParty.
Here is how the Corpus Management window looked after several iterations of this process.

The green stripe icon indicates a reasonably high quality analysis result. Notice that 359 concepts have been extracted from the taxonomy. Since the taxonomy now contains 400 concepts, we have a very high degree of match. That is, 89% of the concepts in the taxonomy also occur somewhere in the 749 documents in the corpus.
The Corpus Management process is iterative (which is how we went from 150 to 400 concepts). At each iteration the analysis informs the taxonomist about improvements that could be made; breaking up portmanteau concepts, promoting extracted terms to full concepts, and so on. The taxonomist refines the taxonomy and re-runs the corpus analysis. At each iteration the quality of the analysis improves, and the proportion of concepts extracted compared with the total number of concepts should approach a constant value. Bear in mind that this is not an exact science, and the number of documents, the size of the documents, the initial size of the taxonomy and the number of iterations is more a matter of experience and gut feel than a calculation.
At the end of the process the combination of the improved taxonomy, the corpus of documents and the analysis gives us a powerful information source for building the content graph. In part 4 I will describe the semantic middleware that will manage this.
Aside – discrepancy in document numbers? ^
As an aside, you may notice that Figure 3 above lists 948 pdf files. And yet we only (only!) have 749 documents in the Corpus Management document set. There were a number of reasons for this.
- In some cases there did not seem to be a valid pdf at the calculated endpoint, so there was nothing to retrieve.
- Some duplication arose from an article being published in more than one category.
- In some other cases, the language used in the arXiv document was not English. A key aspect of Corpus Management is defining a corpus language. I used English as the corpus language, and as a result attempts to upload a document that had been written in, say, French failed.
Although slightly irritating, this makes some sense when you bear in mind that we have a taxonomy in English. Analysing a French text and comparing to an English taxonomy would have unpredictable results.
Assistive classification using the Extractor ^
I briefly mentioned the PoolParty Extractor earlier. Now it’s time to use it with some real content in order to suggest how best to classify the content.
The principle behind the Extractor is similar to Corpus Management. Take a piece of content and analyse it for significant words or phrases. In this case, the analysis is bolstered by the presence of Corpus Management results. It’s best illustrated with an example. The primary route to using the Extractor is via the PoolParty api. However, there is an interactive UI to carry out test extractions. The screenshot below shows the interactive Extractor window. I'll be spending a lot more time with the Extractor api in the fourth article.
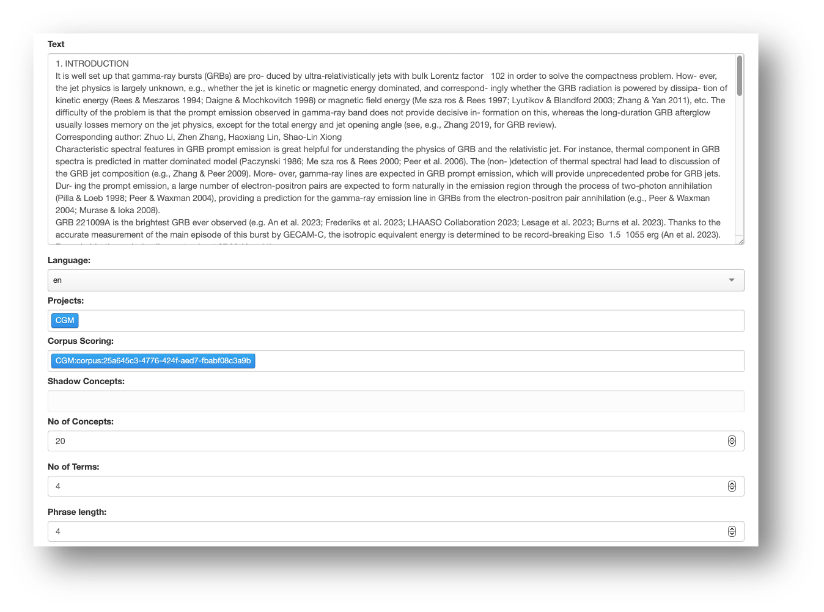
Setting up an extraction involves setting the project, language, corpus analysis, required number of concepts and extracted terms.
Choosing the Extract button (slightly out of view in the screenshot above) results in this results window.

At this stage, a quick scan through the text should reveal that the extracted concepts have matches within the pasted text.
It’s important to stress that this is not auto-tagging; in my view it is not wise to leave the classification process entirely up to software. The Extractor makes reasonably good suggestions for matching concepts, but it’s not perfect. As a consequence, when I come to constructing the classification component of the content graph, I will rely more on human insight than software judgements!
The best way to approach this, I think, is what I call assistive classification; allow the system to suggest good matches based on the corpus and extraction tools, and allow the human to decide which ones are relevant. In the next article I will show how I did this using semantic middleware built in Xojo.
End of Part 3 ^
At this stage our content graph is developing nicely. We have information objects dealing with content and authors, and we know how to link them together. We have a SKOS taxonomy that has been enhanced by analysis of its fit to this same set of information objects. We have checked the ability of the PoolParty Extractor to suggest concepts that are suitable for classifying content objects, understanding that the final say must come from the human. The next step will be actually running some classifications and identifying plausible concepts to match the content. I will be diving deep into the use of Xojo to work with the PoolParty Extractor. I will do this by building a semantic middleware program that knows how to talk to the components of the content graph and can process the information meaningfully. That will be the subject of the next article.