
Building a content graph
Organisations that work with content-rich information systems often have to contend with two major problems:
- How to find existing content
- How to make new, re-usable content
The first problem is usually addressed, with varying levels of success, by full-text searching. The second is often not addressed at all, and I'll have more on this later. To deal with the issue of searching first; this problem is not restricted to the internal needs of organisations; everyone deals with the problem of information searching.
For most people, searching is synonymous with Google, and for nearly a generation Google has dominated content searching. However, it is becoming increasingly clear that this traditional model of full-text searching has diminishing returns as the content base becomes larger and more diverse in subject matter. As an example, here is a typical traditional Google search result.

Figure 1. Classical Google search results list
A typical search will retrieve many millions of results, as pages of lists, of variable quality and relevance. This illustrates the key problem with full-text searching; a search engine doesn't know what you are looking for, it only knows what you type. Aside from paid-for / promoted content hits, which often undermine the value of Google search results, the fact that Google provides high quality results (at least, we hope it does) relies on algorithmic refinement and the input of many human beings. Even Google has recognized this, with the recent introduction of "infoboxes" to search results. Here is the current full results page for the search shown above.
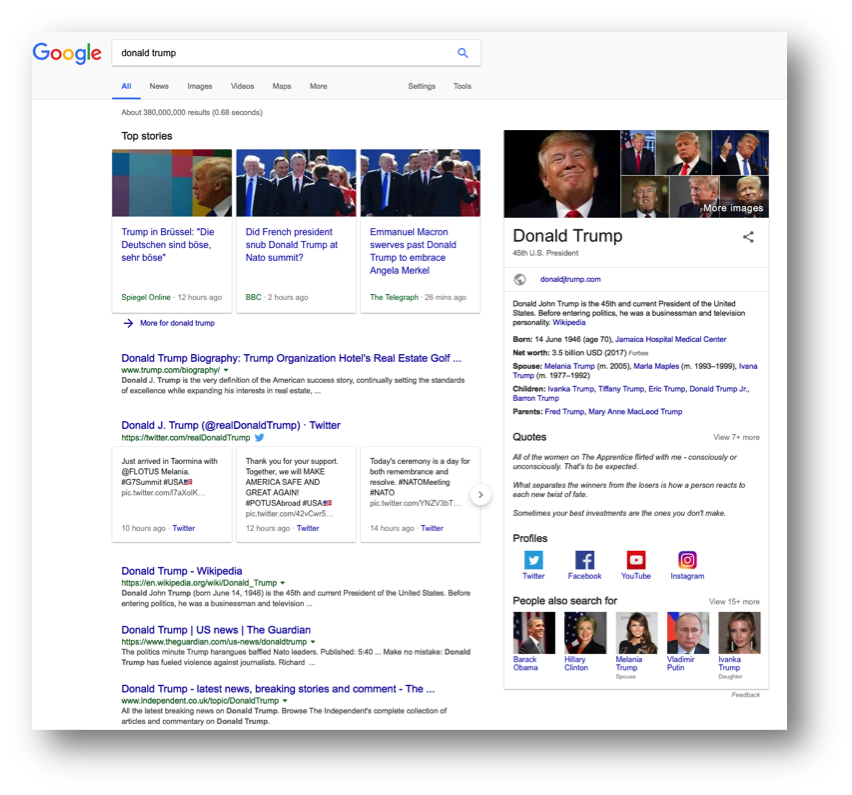
Figure 2. Google results using an infobox
This shows Google's first steps to a more semantically-rich result; the Google Knowledge Graph. As well as the 380,000,000 straight results, there is a range of other pieces of information, such as birth date, net worth, pointers to other related people and so on, in a sidebar (or infobox). Behind the scenes, Google apparently uses a lot of manual input to build infoboxes, but there is also increasingly a real semantic structure in the process of development.
In one sense, Google has been dealt a bad hand, because much of the material that it is tapping into is essentially plain narrative text, and thus unstructured. It's hard to retrospectively build in structure, which is why so much manual intervention is needed. The same is not necessarily true for information systems within organisations. For internal information the organisation has the advantage of being in control, and can determine the amount and nature of content structure. Appropriate content architecture and content architecture modelling helps not only with re-use (more on this later), but also with greater precision in discovery. If we know that, for example, a content item includes "Heading" and "Author" components, then we can interpret the data stored in those components more confidently and precisely. It's easier to know that a piece of text contained within an Author component represents the name of an author.
But there is a further and much greater opportunity; structured classification of content.
Content classification
Regardless of how far we decide to break down content into defined components, we can gain much more precision and value from our content if we can also classify that content using taxonomies. Further, if we can include some semantics in the classification, we will know much more about that classification. Further still, if we can use classification based on a common, shared classification scheme then we have a way to link information objects across different information systems, via their common classifications. It's a step towards a linked-up enterprise; a knowledge network.
Content re-use
Turning to content re-use; organisations often don't do it, because the content is in the wrong form. Content tends to be monolithic and not broken down into re-usable chunks. Content is also usually created for the immediate needs of the organisation, rather than with a strategic perspective of the future usefulness of the content. Frankly, it's less work to just create the content over again.
This is partly a problem with organisational culture; you cannot force an organisation to think strategically. This is especially true if, as is the case with some publishing companies:
- there is pressure to produce content to deadlines, so that authors and editors perceive that they have no time to tag, and
- the return on investment (ROI) comes from the first publication of the content, so there is no imperative to re-use (why bother designing for reuse when you've already recouped your costs?)
Dealing with these cultural factors is beyond the scope of this article, though you probably have an idea of where I stand on this! However it is possible to add support for strategic content re-use through good content architecture. Whether the organisation is ready to use it or not, re-use is available.
A very good way to approach this problem is to use a CMS that allows for the construction of structured content types. In other words, you create your structure and the rules for construction of content within the content management system itself. The enterprise content management system Drupal is a very good example of this approach. I'm not going to describe Drupal content types in detail here; but in overview, if you wanted to create and manage content that has, say, a title, a dateline, an author, a teaser, two or more paragraphs of text, an image and at least one category, then you can define a custom content type that will do that. You can enforce the content design by employing validations and constraints, ensuring that your content conforms to your specified design.
Extending the design process, it is possible to combine together a number of content types to assemble into a master document. This can be done by pulling together a set of content items into a larger "view". That view can include order, structure and presentation/layout rules.
So it is possible to design content objects with the appropriate degree of granularity, and then bring them together into larger aggregations of content in different ways to deliver to different output channels. This approach is key to content re-use.
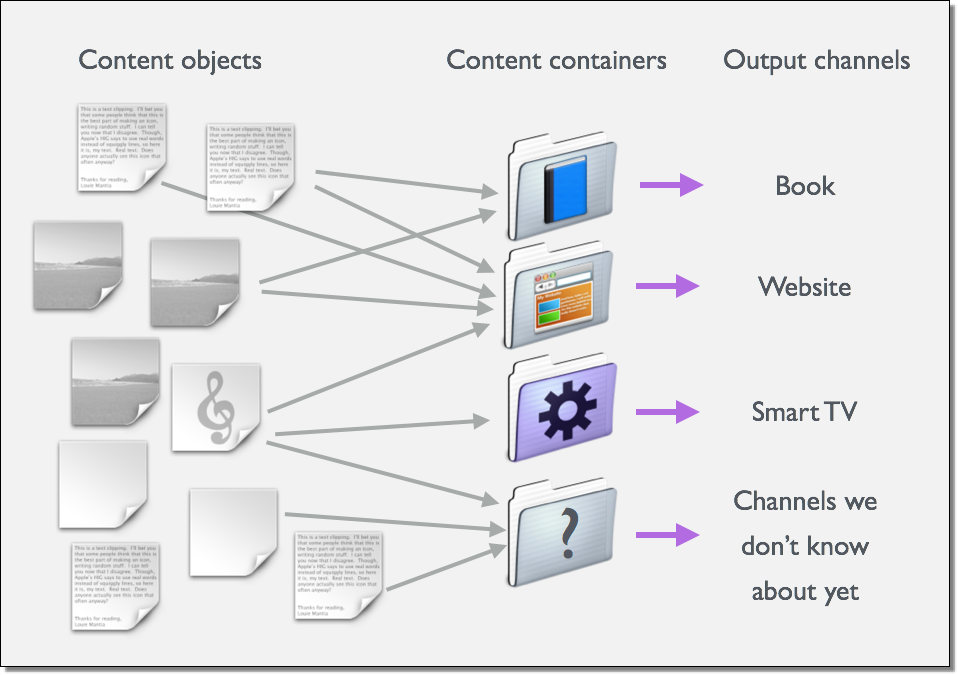
Figure 3. A model for granular content delivery through containers to channels
Linking everything up
I've lost count of the number of times that I've heard arguments along the lines of "Connecting everything together is easy. Just put everything in one system and it will all link up". By "one system", by the way, the speaker usually means "my system". The trouble is, this is almost never a practical answer. Organisations have information spread across relational databases, structured and unstructured content, in many different repositories. Technical barriers to one side, human nature means that data "owners" are reluctant to give up control over "their" information. The monolithic "One System to Rule Them All" argument just doesn't work in the real world.
So what can we do if we want to link everything together? My approach is also simple in its own way:
- Leave your information where it is. Don't try to put everything in one repository; it's a futile exercise! Just make sure that it's accessible via web technologies.
- Make sure that every piece of information that you want to manage has a globally unique identifier. Actually, these need to be Uniform Resource Identifiers (URIs).
- Create a semantic information model that describes the important information in your enterprise. Build it in an enterprise taxonomy.
- Use lightweight, microservices-like connectors to create semantic triples. These will capture the relationships between the different information objects in your environment, and store them in a graph database.
- Use lightweight discovery services to explore your graph database and pull out information and insights.
You may notice a similarity between this five-point plan and the Semantic Web Five Star model. It's not coincidental; both are about powering up your information using structure and meaning.
Making this evident to users
While there are clearly practical steps that organisations can take to move towards improved discoverability and re-use, it is difficult to demonstrate this to those organisations. The different components, such as structured content management systems, SKOS/RDF-based taxonomy management systems and RDF-based graph database systems, are all available, but integrations are thin on the ground.
This is the background to our development of the Content Graph Explorer.