
Just enough SKOS
In this article I'll be describing the Simple Knowledge Organisation System (usually abbreviated to SKOS, and that's how I'll be referring to it from now on); what it means, how it is put together, how it is used in practice and why it is important. I've tried to take a number of different angles to describe it, and hopefully at least one of these will make sense to you. I'll start with the high-level view and get to more detail later in the article.
If this is not enough and you are looking for the extra mile of detail, take a look at the W3C website documents about SKOS; you'll find everything there that you could possibly want to know about it, and maybe more than you want to know!
Who should read this
If you are a business user who wants to understand enough about taxonomies to make credible decisions, but have no need to become a professional expert, this document is for you. If you are a taxonomist and want to know more about how taxonomy formats link to knowledge graphs, there's something here for you too.
The SKOS elevator pitch
SKOS is a format for structuring taxonomy information so that it has context and meaning. We call this “semantically rich” information.
Taxonomy structures are naturally hierarchical; starting with the most general, and becoming steadily more specific (Living thing > Animal > Mammal > Canid > Dog, and so on). Storing this kind of hierarchical information is made much easier if you do it in SKOS, since SKOS offers simple ways to show that one thing is a more specific type of another thing (“a border terrier is a type of dog”).
SKOS also conveys meaning (or “semantics”); when you have one thing that is linked to another, you can specify not just that they are linked, but how they are linked.
Store your taxonomy in SKOS format and you will have semantically rich information (that is, information that is rich with meaning) in a W3C standard, re-usable structure, with a clear hierarchy and room for storing lots of useful metadata. You'll also have created the foundation for connecting distributed information objects like people, documents and processes as part of an enterprise knowledge network.
The rest of this article goes into exactly how SKOS helps in achieving this. But first, I want to go a little way into the “why”; exactly what makes SKOS useful, and what kinds of business problems does it help to solve?
What problems does SKOS solve?
Most organisations start their journey into taxonomies with Excel (some never go anywhere else, and unsurprisingly get little benefit from those taxonomies). A spreadsheet is an initially compelling tool for building taxonomy structures; the row and column approach apparently lends itself well to storing hierarchies. Here’s an example; a partial taxonomy of products and services that might be relevant to the banking sector as it might look in a spreadsheet.
| A | B | C | D |
|---|---|---|---|---|
1 | Products and services |
|
|
|
2 |
| Banking products |
|
|
3 |
|
| Bank accounts |
|
4 |
|
|
| Current accounts |
5 |
|
|
| Savings accounts |
6 |
| Savings and investments |
|
|
7 |
|
| Savings |
|
8 |
|
|
| Savings accounts |
9 |
|
| Investments |
|
10 |
| Mortgage and loan products |
|
|
11 |
|
| Mortgages |
|
12 |
|
| Loans |
|
13 |
| Insurance products |
|
|
14 |
|
| Mortgage insurance |
|
15 |
|
| Travel insurance |
|
16 |
|
| Life insurance |
|
All of the things in this table fall under the heading of Products and services. Some of them are Banking products, others are Savings and investments, and so on. Each row has one term, and the columns define the hierarchical levels.
When developing a taxonomy, a spreadsheet makes good sense at first glance. The hierarchy is clear, it is human-readable, and it is easily edited.
Look closer though, and problems start to emerge.
- How do we use this for classifying content? It may be feasible to import this taxonomy data into an information management system. But then how does this work in terms of management or governance? Where is the authentic version maintained?
- Being easy to edit means that it's hard to keep track of changes.
- There isn’t any obvious additional metadata. There is a term called Investments, but no indication of what that means.
- How do we identify synonyms? How do we include equivalent words for this term in different languages?
- The most important missing piece of metadata is any kind of unique identifier. We can’t rely on the text of the term itself as an identifier because the term may appear more than once (e.g. Savings accounts), and because the term text itself may change over time.
- What happens when a term belongs in more than one place? Taking Savings accounts again, it belongs under Bank accounts and under Savings. How do we keep track of this kind of (very common) situation where a single term should occur in more than one place (known as a polyhierarchy)?
- How do we capture the idea of relatedness? The terms Mortgages and Mortgage insurance are related, but there is no way to specify this relation.
So how does SKOS solve these problems?
First, and most important, a SKOS concept is different from a term in a spreadsheet. A term like Savings accounts is transformed in SKOS into a concept, an information object with its own metadata:
- It has a unique identifier (a Uniform Resource Identifier or URI). This identifier is the globally unique machine-readable identifier for the concept. It enables a single concept to appear in multiple locations in the taxonomy; the URI helps to specify that Savings accounts under Bank accounts is the same concept as Savings accounts under Savings.
- The URI is the key to classification of information. Linking the identifier of an information object to the URI for a taxonomy concept is an unambiguous way of tagging the information as being about this concept.
- It has a single preferred label (for a given language). While a URI is the machine-readable identifier, the preferred label is intended for humans to read. Because the URI is the main identifier, the preferred label can vary over time without losing links such as classification to content objects.
- SKOS is multi-lingual by design. Any text property can be stored in any ISO language.
- It has data properties (attributes) such as definitions, synonyms, scope notes and so on. These pieces of metadata enable a reader to get the full picture of the concept and to distinguish it from other apparently similar concepts.
- It has object properties (relations) linking this concept to other concepts. This is how the hierarchy is constructed; Savings accounts has broader links both to Savings and to Bank accounts, and Mortgages has a related link to Mortgage insurance. These are semantic links; the link itself has a meaning.
SKOS data can easily be expressed in the form of a network, which is not easily achieved with a spreadsheet. The SKOS data above can be displayed in a visual graph like this:
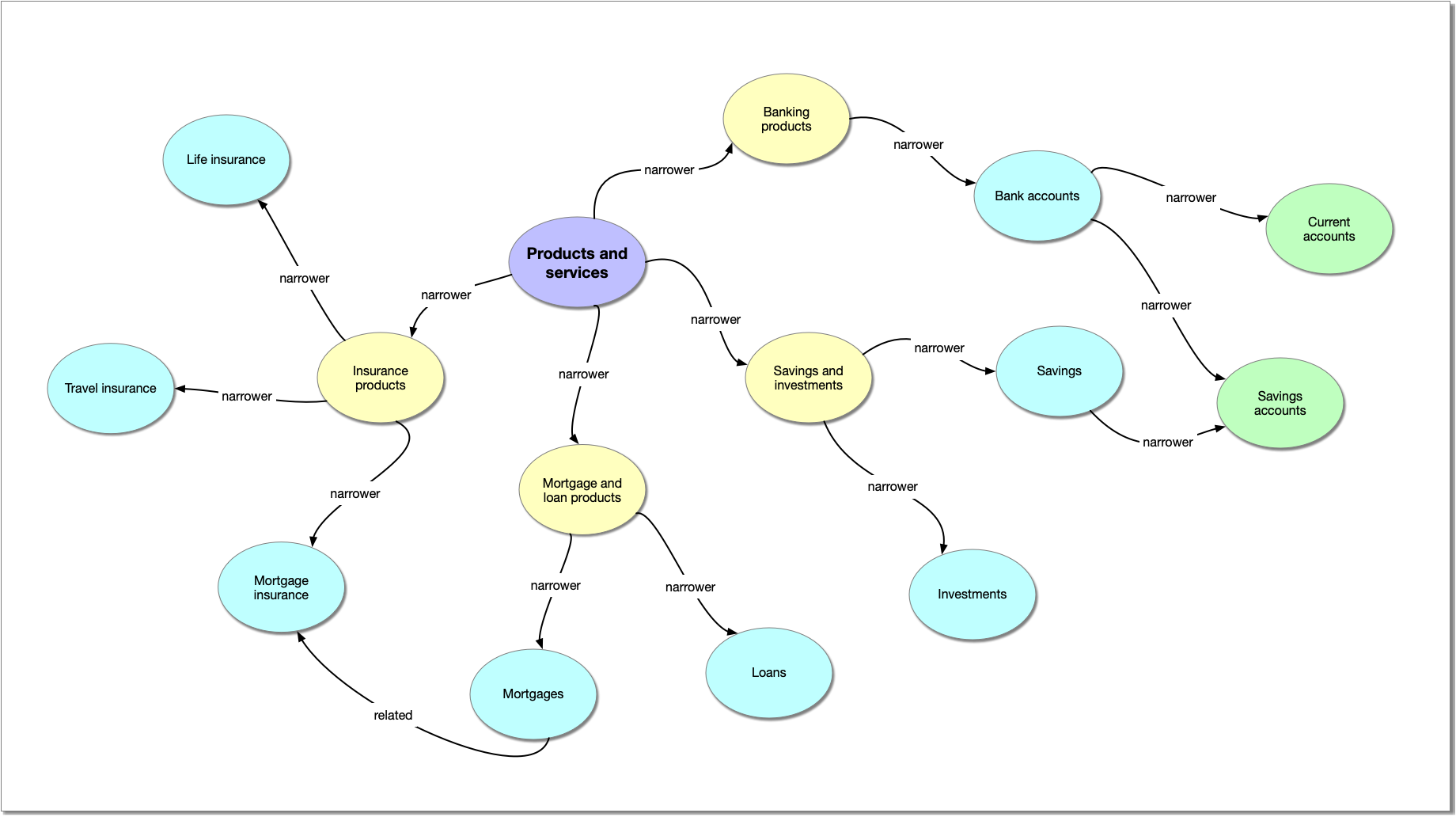
You can see that this data view shows the hierarchical structure, and the related concepts of Mortgage insurance and Mortgages, and also shows that both Bank accounts and Savings concepts have Savings accounts as narrower concepts.
If you are limited to Excel, without a structured data standard like SKOS, it’s difficult to build a rich taxonomy.
SKOS in slightly longer form
SKOS is becoming the de facto standard for managing taxonomy information. It gives you a predictable structure for storing taxonomy concepts in a hierarchy from general to specific; like this:
Animal
Mammal
Canid
Dog
Terrier
Border TerrierIt also lets you link related concepts together easily:
Border Terrier is related to Lakeland Terrier
SKOS also allows you to store other metadata for concepts, such as synonyms and descriptions. A SKOS concept might have a description like this:
The Border Terrier is a small, rough-coated breed of dog in the terrier group. It is bred as a fox and vermin hunter.
Having a description included with the other information for a concept means that you have a way to be unambiguous about its meaning. You can distinguish a concept called “Java” (description: “An island of Indonesia”) from another concept called “Java” (“A programming language”).
SKOS provides a consistent and extensible format for managing both simple and complex taxonomy data.
SKOS in excruciating detail
One of the things that frequently confuses people about SKOS is that it seems quite an abstract topic; it seems hard to pin it down as a concrete thing that you can analyse and manipulate. Hopefully I can change that with this article. So what is SKOS?
- It's a way of holding taxonomy and thesaurus information.
- It's a data format.
- It's a flavour of the semantic web standard called RDF.
- It's an ontology.
It's all of these things, and that is why it's confusing. So let's take these one at a time, and see if we can get some sense out of it all.
SKOS is a data structure for storing taxonomy and thesaurus information
Taxonomy and thesaurus management are the key design features of SKOS. You can easily build data structures that are hierarchical, cross-linked, and containing rich descriptive data. The result is that they provide context and meaning (in other words, semantics).
A SKOS concept has pre-defined fields (actually, properties) that allow you to give a concept:
- a unique identifier (called a uniform resource identifier or URI)
- a preferred label (for each language required)
- zero or more alternative labels (also available in multiple languages)
- a variety of other string properties such as scope notes, editorial notes, hidden labels and definitions, also in all required languages
- broader, narrower and related links to other concepts, plus a variety of other links such as exactMatch, closeMatch, relatedMatch and so on
- links to one or more concept schemes that act as a container for the concept
By using SKOS as the data structure for a taxonomy you benefit from a W3C standard that is interoperable with other open semantic web related standards.
SKOS is a data format
You can create SKOS data files. Although SKOS is this strange, apparently abstract information model (see below), no one is silly enough to think that we don't have to use it in the real world. So most of the environments that create and manage SKOS data can also save it out into readable file formats. IT geeks often call this process serialization. To you and me, this just means putting the data into formats that can easily be read by other programs. There are many such formats, with weird names like Turtle, Trig and Json, but we'll just consider one of them for now; XML.
You are probably familiar with XML as a standard structured data format. XML uses things called elements (named things in angled brackets, like this: <data>abcdef</data>) and attributes (metadata applied to elements, like this: <data type="alphabetical">abcdef</data>).
XML is hierarchical; you can have a structure like this, in which an element can contain another element, which contains another element, and so on:
<book>
<front matter>
<acknowledgements>[...]</acknowledgements>
<foreword>[...]</foreword>
<tableofcontents>[...]<tableofcontents>
</front matter>
<part id="1">
<chapter id="a">
<section id="i">
[...]
</section>
<section id="ii">[...]</section>
</chapter>
</part>
</book>This structure can be explained like this:
<book> | The most general, topmost level of the data. Contains one <front matter> element and one or more <part> elements |
<front matter> | The container for the text which goes in the front of the book; not part of the actual book content. Contains one <acknowledgement>, one <foreword> and one <tableofcontents> elements. |
<part> | The largest division of content in a <book>. A <section> has one or more <chapter> elements. |
<chapter> | A chapter is a collection of pieces of content on a particular theme. A chapter has one or more <section> elements |
<section> | A <section> is a part of a <chapter> that is intended to cover one specific aspect of a <section>. It contains elements for text, images and other assets belonging to the section. |
[ and so on ] |
|
So a <book> element contains a <part> element which contains a <chapter> element which contains a <section> element which contains real content.
I call this an explicit structure; that is, the hierarchy is spelled out by the structure you can see; the indented structure shows the hierarchy. It is unambiguous, and also human-readable; just by looking at this indented structure you can discern the structure of a book.
However, XML can also use implicit hierarchies. Rather than using the containment structure of elements, it is possible to imply hierarchy using attributes. Take a look at this (this is just a little chunk from a larger structure, for clarity):
<myXML uri="http://myUri/1"> <narrower uri="http://myUri/3"/> <narrower uri="http://myUri/8"/> <narrower uri="http://myUri/9"/> <prefLabel>Front matter</prefLabel> </myXML> <myXML uri="http://myUri/3"> <prefLabel>Acknowledgements</prefLabel> <broader uri="http://myUri/1"/> </myXML>
This describes a structure that is equivalent to the explicit hierarchy above, describing just the Front matter and Acknowledgements elements. However, in place of the hierarchical elements, we have an implicit structure that uses broader and narrower elements. The Front matter element has a narrower relation pointing to the Acknowledgements element, which in turn has a broader relation pointing back. Like the hierarchical XML example above, it is also unambiguous (at least for a computer) though it is not so easy for a human to understand.
Here is a table like the one above, describing this structure.
<myXML> | The topmost element, representing just one thing. Has an attribute to identify it. It also has properties that connect it to other things; the name of the property is important, as it defines the type of connection to the other thing. |
<narrower> | A property that connects the current thing with another, more specific thing. |
<broader> | The inverse of <narrower>; connects the current thing with a more general thing. The two go together to show that these two things are interrelated. |
<prefLabel> | An element that has a human-readable name for this thing |
Now, you may be thinking something like "What? How is this an improvement?". A fair question; it's much more verbose, and it's not as easy for a human to see the overall structure.
But look closer. When you define a structure like this, you put all of the elements in the structure at the top level; there is no recursive hierarchy to worry about (recursion is the enemy of software developers). Each myXML element stands alone, but tells you where it belongs in the hierarchy through its broader and narrower properties.
The elements are now independent, instead of dependent on where they sit in the code. They can be rearranged and deleted, without losing the meaning of the other elements.
It's more long-winded, and it's not so easy to read for human eyes, but that doesn't matter; this is not meant to be read by humans, but by computers. Each little chunk tells you where it belongs ("here's my parent; here are my children"). So any computer system can re-construct the real hierarchy very easily just by reading through a simple stream of top-level XML elements and their implicit hierarchy.
This kind of flattened structure also makes it easy for a computer to maintain the hierarchy. You can simply add in new top-level elements and say where in the hierarchy they belong. There is no need to graft an element in between two existing elements. Rather than edit three elements, you just edit one.
Finally, and in a sense most important; an implicit hierarchy means that while you can display a collection of concepts in a tree structure, they can equally well be displayed as a network or graph. Take another look at the banking information structure above; you can look at it as a hierarchy or a knowledge graph, because it is both.
For now, the key thing to be clear about is that SKOS uses a flat data structure with an implicit hierarchy. And that flat structure makes life a lot easier.
SKOS is also RDF
Ah, RDF. Another obscure piece of terminology. RDF is an abbreviation for Resource Description Framework. I know that still doesn't help. Let's look at it in more detail.
RDF is intended to be a comprehensive approach to describing Semantic Web information. Central to the Semantic Web is the principle of semantic triples. A semantic triple (this is about as deep down this definitional rabbit hole as we are going to go!) is a very simple data structure that links a subject with an object via a verb. Take this example:
Ian knows John
This is a statement that connects a subject (Ian) with an object (John) using a meaningful verb (knows). Now you could envisage having a huge number of other similar statements:
Ian knows John John knows Jesse John likes pizza Ian dislikes pizza [and so on]
This logical mechanism for storing all of these statements also gives you a way to explore them. Each of the three parts of a triple is tractable; you can ask "What facts do we know about Ian?" "Who does Ian know?", "Who likes pizza?", and so on. You also have a way to follow networks of links;
Ian < knows > John < knows > Jesse
This last example indicates two properties of this type of data. First, it can be symmetric, meaning that the link works both ways; if Ian knows John then John must also know Ian. Second, it can be transitive, allowing a chain of links to be traversed, from Ian through John to Jesse (there is an implied secondary level of knowledge; a bit like the levels of connectness in LinkedIn).
In a nutshell, this is RDF; it's a data standard that allows you to build large, connected collections based on the simple unit of a semantic triple. RDF allows you to build out massive collections of linked triples, which form the underlying structure for knowledge networks.
So here is the connection to SKOS. When you create a taxonomy using SKOS, you are creating a collection of semantic triples. We can take a part of the structure shown above:
<myXML uri="http://myUri/1"> <narrower uri="http://myUri/3"/> <narrower uri="http://myUri/8"/> <narrower uri="http://myUri/9"/> <prefLabel>Front matter</prefLabel> </myXML>
and rewrite it like this:
myUri/1 has narrower myUri/3 myUri/1 has narrower myUri/8 myUri/1 has narrower myUri/9 myUri/1 has prefLabel "Front matter"
It turns out that SKOS has been designed to be an expression, or flavour (my words, by the way) of RDF. As an ontology SKOS uses this namespace: http://www.w3.org/2004/02/skos/core/ (usually reduced in taxonomies to the prefix skos:) and you can download the full reference implementation from here: http://www.w3.org/TR/skos-reference/skos-owl1.dl.rdf
This is not simply a choice between one document format and another. RDF was designed to allow people to develop information models based on classes (types of thing) and properties (the ways in which one thing is related to another thing). Something that often trips up people new to RDF is that the same core information (which you might call an abstract model) can be represented as concrete outputs in many different ways; as XML or any of a range of structured text formats. These different output formats are called serialisations. Serialisations may look quite different from each other, but each conveys exactly the same information, and each matches the more abstract model of RDF. This is a massive strength of RDF; you can build the abstract model and then deliver the data you need out of it in the format you need.
One of the key design features of RDF is that it can import any ontology from any other RDF data source. That is to say, RDF is inherently extensible. Rather than, say, design your information model to have its own classes to represent people, you can simply import the Friend of a Friend (FOAF) ontology, and you have access to the classes and properties of FOAF in your model. Since SKOS-based taxonomies conform to the SKOS ontology (of which, more later), which is based on RDF, then they are also extensible. The consequence is that you can enrich your taxonomy using classes, object properties and data properties from other RDF resources.
In summary; RDF is the core of the Semantic Web, and SKOS is a form of RDF. Build your taxonomies using SKOS and you make it easier to build those taxonomies into a knowledge network.
It’s time to introduce another new piece of terminology; the knowledge graph. A graph in this context is a collection of connected things, and in the case of a knowledge graph, the things are information objects. A taxonomy of concepts is itself a graph. The image above is a graph. A collection of semantic triples in a common repository is a graph; in fact the systems used to manage collections of triples is often called a graph database. When I create a knowledge network I'm also creating a knowledge graph.
SKOS is an ontology
I've written about ontologies in the past, so I won't reiterate all of the details here. The important thing to grasp is that an ontology is a model, or a template, or a recipe, for a piece of structured information.
At its simplest, an ontology has things (called classes) and relationships between those things (called object properties and data properties). So let's look at SKOS as an ontology. I’ve described the key features here; you can see the full feature set at the SKOS reference page: https://www.w3.org/2009/08/skos-reference/skos.html.
Classes
SKOS defines two main classes; Concept and ConceptScheme. That is to say, in a real-life taxonomy based on SKOS, the things that are managed are either SKOS concepts or SKOS concept schemes.
- A concept conveys just one idea, or topic; a country, a language, a technical skill.
- A concept scheme is a container for concepts; countries, languages, skills. As a general rule, a concept scheme should contain concepts that are comparable in some way (a languages concept scheme ought to contain concepts that each represent a single language).
A concept in a real-life SKOS-based taxonomy uses object properties and data properties that have been defined in the SKOS ontology for a SKOS Concept. Similarly, the concept scheme in a real-life taxonomy, gathering together its concepts, conforms to the object and data properties defined in SKOS.
In addition to classes, the SKOS ontology includes two types of properties; object properties and data properties.
Object properties
An object property is used to link one thing in an ontology to another thing in an ontology. In the SKOS ontology, object properties are used to link concepts to concepts, and concepts to concept schemes. These object properties are the key to defining the hierarchical and linked nature of a SKOS-based taxonomy. When you see a broader-narrower link between two concepts in a taxonomy, or when you see a topConceptOf property linking a concept and the concept scheme where it belongs, you are seeing object properties.
Here is a partial list of the object properties defined in SKOS.
Object property | Notes |
narrower | Links a broader, more general concept to a more detailed, more specific concept (e.g. Dog > skos:narrower > Labrador) |
broader | Links a concept to a more general "parent" |
related | Links a concept to a similar concept (e.g. Border Terrier > skos:related > Patterdale Terrier) |
topConceptOf | Links a concept to the immediate parent concept scheme(s) where it belongs. Only used for topmost concepts in a concept scheme |
inScheme | Links a concept to the concept scheme where it belongs. The concept does not have to be a top concept. |
|
|
Data properties
Data properties are used to link a thing (a concept or a concept scheme) to a piece of data (i.e. something that does not need to be treated as another rich object). For example, a concept has a variety of text properties, like preferred and alternative labels. These really are just pieces of text, and thus are managed using data properties. Data properties may have a specified format; for example, a concept may have a created date. Since all data stored in a taxonomy is stored as a string, there needs to be a way to indicate what the data format should be. This is done using a modifier; there is an example in the table below of how dates are managed Here is a partial list of data properties used in SKOS.
Data property | Notes |
prefLabel | Used to hold the primary text label used to describe a concept |
altLabel | Used for concept synonyms |
definition | Holds a long form definition for a concept |
title | Used to describe a concept scheme |
created | Actually http://purl.org/dc/terms/created. It is stored in this format in order to specify that it is stored as a string but really is a date: "2019-04-09T21:53:42Z"^^xsd:dateTime |
Final thoughts
So that's it. SKOS in summary through to SKOS in depth. I hope that at least one of these different perspectives helps to give you the level of insight that you need into this important information standard.