
Using SPARQL queries with PoolParty
This is an introduction to using the SPARQL query language to talk to PoolParty. PoolParty stores taxonomy project data in the form of graph databases, with the individual chunks of information stored as semantic triples. Here is an example of a set of triples as they are stored in PoolParty; this is a set of triples for a single concept:
<http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Government> <skos:prefLabel> "Government"@en . <http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Government> <rdfs:type> <http://www.w3.org/2004/02/skos/core#Concept> . <http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Government> <skos:definition> "The institution of government and its attendant processes."@en . <http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Government> <skos:narrower> <http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Central-government> . <http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Government> <skos:narrower> <http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Executive-government> .
These triples are written in a format called N-triples, and it's worth just unpacking this data a little. The listing above contains five triples, all of which contain information about the Government concept in our General Thesaurus. So each of these triples begins with the Uniform Resource Identifier (URI) for that concept: http://tellura.poolparty.biz/tellurasemantics/generalthesaurus/Government. In each triple this URI is followed by a predicate (which is a sort of linking verb, and is also a URI). The first triple above, for example, has skos:prefLabel as its predicate. That is followed by "Government"@en, and then a dot. This triple translates to "this concept has an English language label, based on the SKOS ontology, of "Government". Similarly, the second triple tells us that this concept is of type Concept. Semantic triples manage to pack an amazing amount of information value into a very simple design.
Anyway, given that PoolParty stores all of its information in this information-rich format, it would be nice if we could retrieve that information. And we can, using SPARQL. Every project in a PoolParty instance has a SPARQL endpoint, which is a geeky way of saying "a place where you can send a SPARQL query".
SPARQL (pronounced "sparkle") is one of those tooth-grindingly irritating recursive acronyms; it is an abbreviation of SPARQL Protocol and RDF Query Language. Anyway, irritation aside, it is a language that allows you to send queries to a triple store and retrieve structured information as a response. The book Learning SPARQL by Bob DuCharme is a good place to start learning how to write SPARQL, and you'll find plenty of other learning resources on the web.
Setting things up
It is a fairly straightforward process to create software using SPARQL, but there is a certain amount of set-up to do first.
To run the applications, you should create a PHP (another recursive acronym, short for PHP Hypertext Preprocessor) script with the appropriate name (which will be something like poolparty-script.php) in a folder that can be delivered to a web server. In my case, I used the folder /Users/ianpiper/Sites/pp, as this is a personal localhost folder on a Mac. Other platforms will have different arrangements.
You'll need to download the ARC2 library; this downloads as a zip file, so you will need to unzip this and put the arc2-master folder in the same folder as the script. So the script folder will have the php file(s) and the arc2-master folder (which in turn contain the support files and folders). As an alternative, you might like to use the newer EasyRDF library, also for PHP. You can see an example of how we've used this to build an autocomplete search, in this article.
For each SPARQL-based example, you will need to create a PHP file, and then load that file into the browser. You can simply copy and paste the code from the examples below. Depending on the OS you are using, you may need to modify the permissions of the file in order to get it to run. Assuming all is well the results from the program will be presented in the browser window.
Worked example
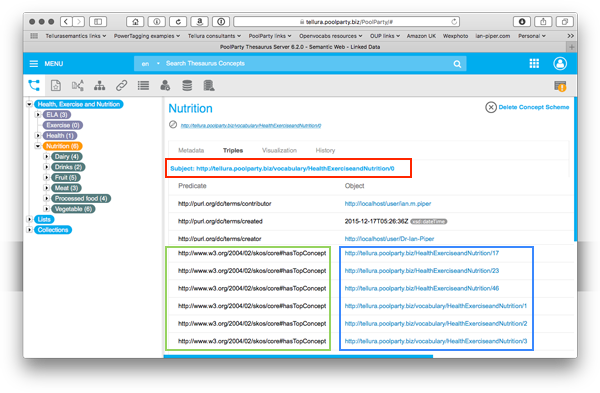
I'm going to illustrate this using a simple example. I built a small taxonomy project called Health, Exercise and Nutrition. This has a project id of 1DDFFAF3-A3D8-0001-199C-18E0E6001315. The project has three concept schemes, covering the main topics of Health, Exercise and Food, but for this example, only the Nutrition concept scheme has been built out. See the screenshot below, in which this concept scheme is selected. The concept scheme has the URI http://tellura.poolparty.biz/vocabulary/HealthExerciseandNutrition/0. The top concepts are visible in the main panel (pale blue background). Here is the normal ("Metadata") view of the Food concept scheme. You can see that it has 6 top concepts.

Here is the Triples view of the same concept scheme. The highlights show the subject URI for the concept (red), the URIs for the predicate skos:hasTopConcept (green) and the object URIs for the top concepts of that concept scheme (blue).
So, to the code. We want to specify the concept scheme, and get back its top concepts. The block below shows the complete PHP code for this example.
<?php
// include the ARC2 libraries
require_once('arc2-master/ARC2.php');
// configure the remote store, using the project identifier
// (in this case HealthExerciseandNutrition) and not the project id (which is 1DDFFAF3-A3D8-0001-199C-18E0E6001315)
$configuration = array('remote_store_endpoint' => 'http://tellura.poolparty.biz/PoolParty/sparql/HealthExerciseandNutrition');
// create the repository using this configuration
$store = ARC2::getRemoteStore($configuration);
// the SPARQL query - we want the top concepts for the concept scheme whose URI is
// http://tellura.poolparty.biz/vocabulary/HealthExerciseandNutrition/0
$query = "
PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
SELECT *
WHERE { <http://tellura.poolparty.biz/vocabulary/HealthExerciseandNutrition/0> skos:hasTopConcept ?concept }
";
// get the response from the SPARQL endpoint
$rows = $store->query($query, 'rows');
echo 'The concept scheme has the following top concepts:' . '<br />';
foreach ($rows as $row) {
echo $row['concept'] . '<br />';
}
?>
Working through this script; after including the ARC2 library, we need to configure the remote repository, via its SPARQL endpoint. The $store variable holds the pointer to this repository, so once set up we can use this as a destination to direct queries.
Next, we need to build up the SPARQL query. This one simply says “get a collection of URIs for the objects that have the predicate skos:topConcept for the subject with the ConceptScheme’s URI”.
The query returns an array called $rows. We can then walk through that array and display each $row result; each result is the URI for that concept.
The figure below shows results returned from the script.

The key point in this example is that you can build up any SPARQL query as the query data, and you'll get back an array of results that you can explore in your application. SPARQL is powerful, and you could build up queries in this way to retrieve almost anything that you want from a PoolParty taxonomy.
Well, that's it for this initial introductory article. I'll be back soon with some other practical applications of SPARQL in PoolParty and elsewhere.