
Using the PoolParty Extractor for assistive tagging
In recent articles I have been describing assistive tagging as a way to blend elements of machine learning with human ingenuity. You may be wondering what efforts you need to go through to make all of that work. Well, to be honest, if you want to achieve a seamless environment for this kind of content classification it is likely to involve a certain amount of integration work between your content management system (CMS) and PoolParty.
However, if you are prepared to get your hands (slightly) dirty, there is a very simple, very quick, low tech way to do this. I'm going to use this technical note to demonstrate exactly how.
The key is a component of PoolParty called the Extractor. This is a little-known user interface that in effect does most of the work of a tagging integration, but does it manually. Here's how it works. Suppose you have a piece of content that you want to tag. Let's say it's an article that you are writing in a CMS like Drupal. You will have an editing interface like this:
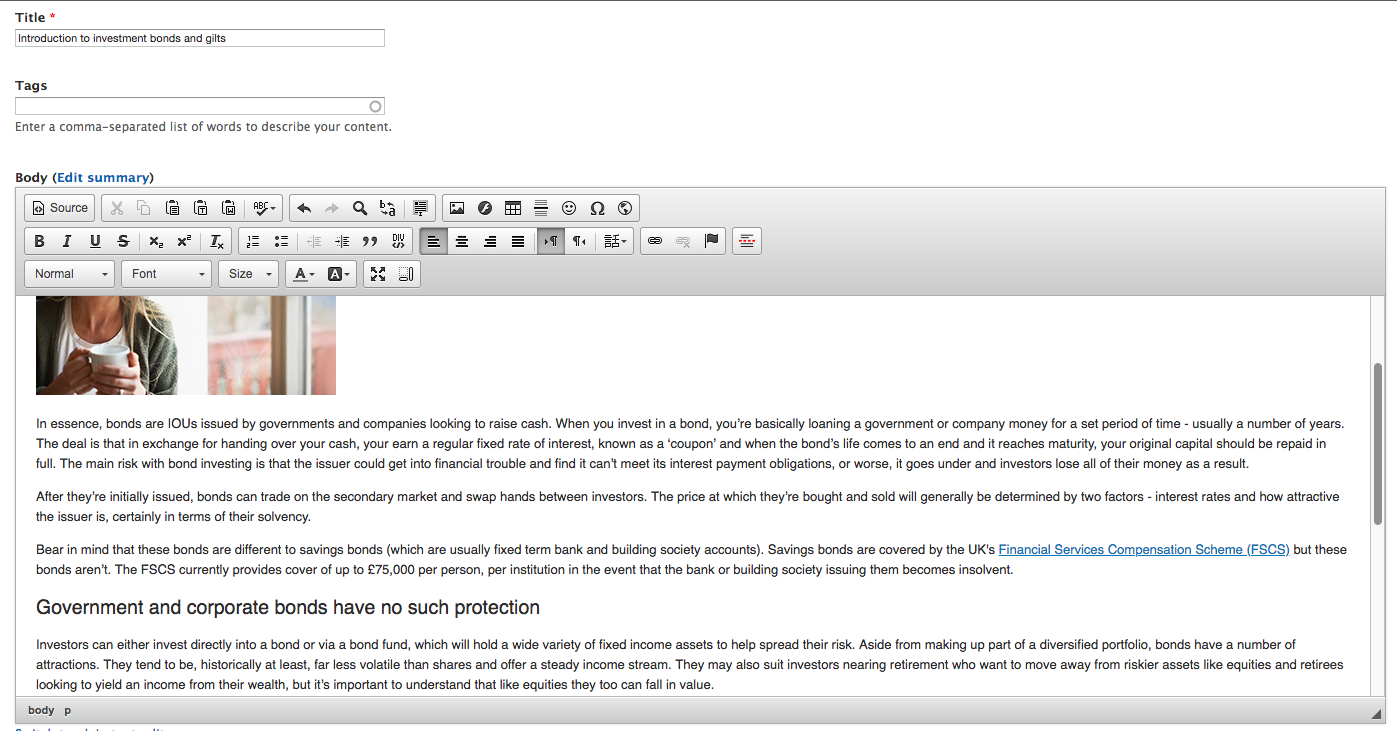
As a subject matter expert, you have an idea of the likely tags for this article, but would like some machine assistance. The first thing to do is to select the text in the editor and copy it to the clipboard. Next, load up the PoolParty Extractor interface. If you have the Extractor as a PoolParty component, you can find the extractor at https://[your-server.com]/extractor/ . You'll see a screen that looks like this (I've anonymised this example):
Click on the Test Extraction button and you'll see this:
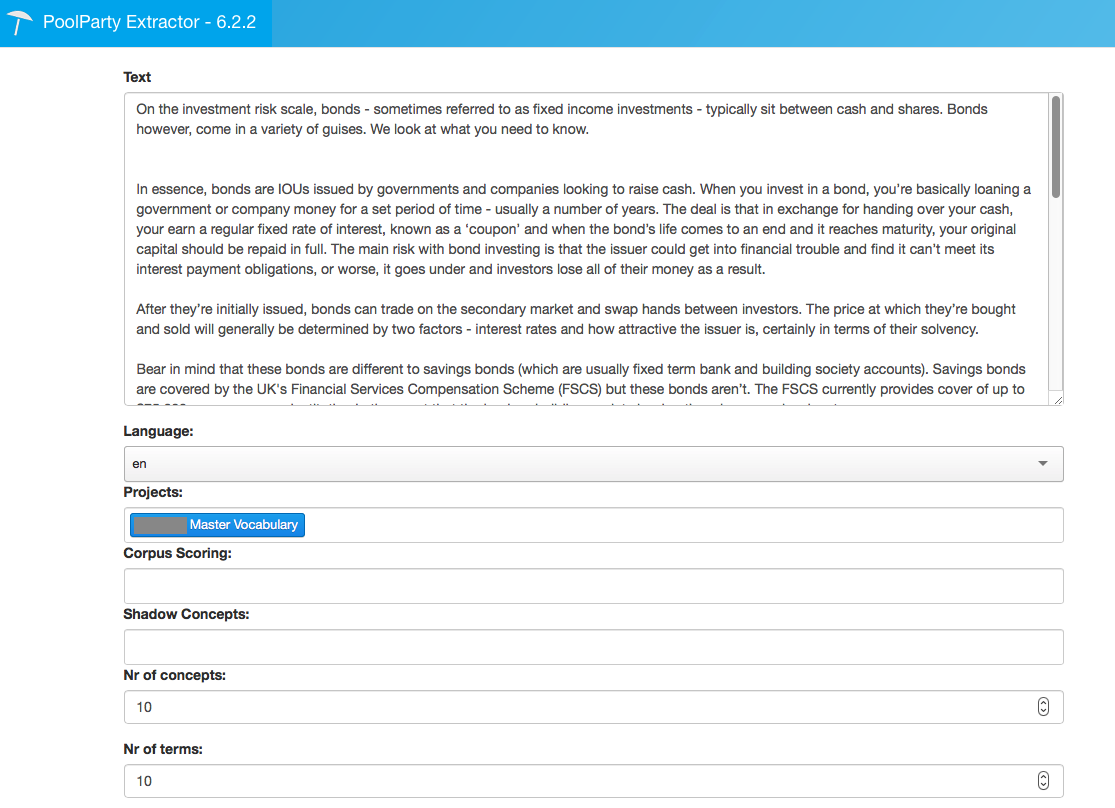
This is the Extractor configuration screen. All I have done here is to paste in my text, specify the language as English (PoolParty is multi-lingual so it's important to define which language you want to use for text mining) and the name of the PoolParty project that contains your taxonomy (anonymised here again).
There are a lot of other advanced settings that you can configure here, but for this demonstration we don't need any of them. Just click on the Extract button at the bottom of the form, and the magic happens.
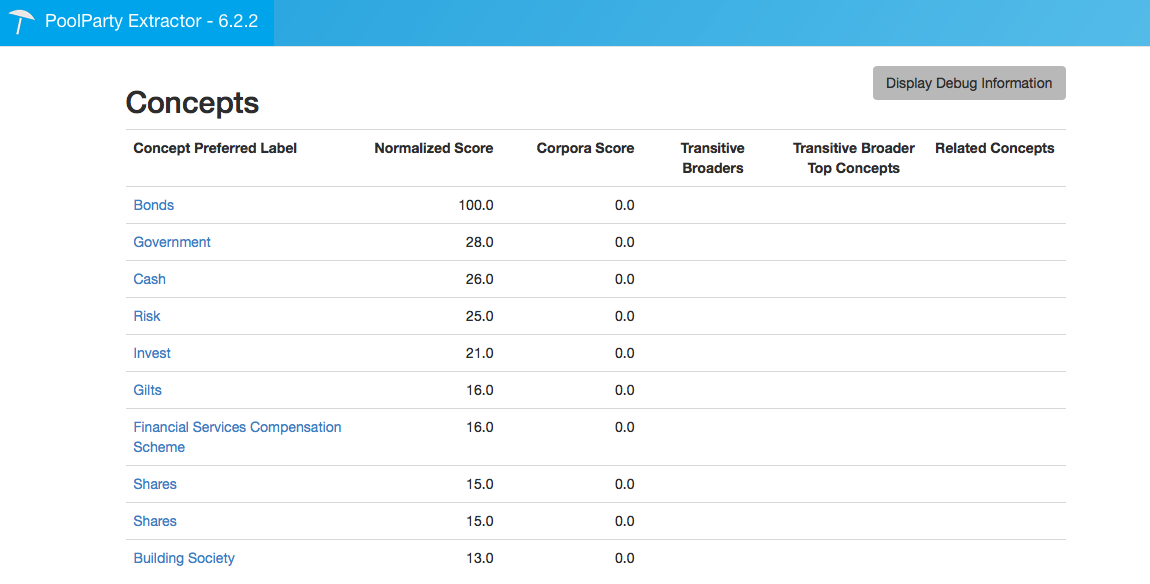
It's not really magic of course. PoolParty has taken the content that I pasted into the form and run its text mining tools over it, comparing it to the taxonomy that I specified. What comes back is a list of the concepts (remember, concepts are not the same as terms) together with some relevance scoring.
As a human subject matter expert of course, you have the casting vote on whether to include any of these suggested concepts in the tagging for the document. But the tagging suggestions that the Extractor provides are normally highly relevant.
Having set up the extractor in this way, it lends itself to some fairly straightforward workflow. You can simply use the back button to get back to the configuration form, paste in your next content item and retrieve its concepts. It's a very easy process with high fidelity. You can make it even better if you do a corpus analysis first, as this will help you to identify shadow concepts. Space doesn't allow for an extensive description of this here, but just get in touch if this is something with which you'd like some help.
Even better, we have developed a number of tools that make the whole process of assistive tagging much smoother. And that's the subject of another article; come back soon for that.